Blog / Discover how Python streamlines your data collection process by scraping Yelp reviews. Learn the steps to automate data collection and gain valuable insights.
28 May 2024
Yelp is an American company that offers information about various businesses and specialists' feedback. These are actual client feedback taken from the users of multiple firms or other business entities. Yelp is an important website that houses the largest amount of business reviews on the internet.
As we can see, if we scrape Yelp review data using a tool called a scraper or Python libraries, we can find many useful tendencies and numbers here. This would further be useful for enhancing personal products or changing free clients into paid ones.
Since Yelp categorizes numerous businesses, including those that are in your niche, scraping its data may help you get information about businessmen's names, contact details, addresses, and business types. It makes the search of potential buyers faster.
The Yelp API is a web service set that allows developers to retrieve detailed information about various businesses and reviews submitted by Yelp users. Here's a breakdown of what the Yelp restaurant API offers and how it works:
The API helps to access Yelp's database of business listings. This database contains data about businesses, such as their names, locations, phone numbers, operational hours, and customer reviews.
Business listings can also be searched using an API whereby users provide location, category and rating system. It assists in identifying or filtering particular types of firms or those located in a particular region.
The API is also helpful for any particular business; it can provide the price range, photos of the company inside, menus, etc. It is beneficial when concerned with a business's broader perspective.
It is possible to generate business reviews, where you can find the review body text and star rating attributed to a certain business and date of the review. This is useful in analyzing customers' attitude and their responses to specific products or services.
Before integrating Yelp API into your application, there is an API key that needs to be obtained by the developer who will be using the Yelp API to access the Yelp platform.
The API is how your application connects to this service, and it has usage limits, whereby the number of requests is limited by a certain time frame. This will enable the fair use of the system and prevent straining of the system by some individuals.
As anticipated there is a lot of useful information and resources that are available for the developers who want to use Yelp API in their applications. This covers example queries, data structures the program employs, and other features that make the program easy to use.

Web scraping Yelp reviews involves using specific tools to extract data from their website. Here are some popular tools and how they work:
BeautifulSoup is a Python library that helps you parse HTML and XML documents. It allows you to navigate and search through a webpage to find specific elements, like business names or addresses. For example, you can use BeautifulSoup to pull out all the restaurant names listed on a Yelp page.
Selenium is another Python library that automates web browsers. It lets you interact with web pages just like a human would, clicking buttons and navigating through multiple pages to collect data. Selenium can be used to automate the process of clicking through different pages on Yelp and scraping data from each page.
Scrapy is a robust web scraping framework for Python. It's designed to efficiently scrape large amounts of data and can be combined with BeautifulSoup and Selenium for more complex tasks. Scrapy can handle more extensive scraping tasks, such as gathering data from multiple Yelp pages and saving it systematically.
ParseHub is a web scraping tool that requires no coding skills. Its user-friendly interface allows you to create templates and specify the data you want to extract. For example, you can set up a ParseHub project to identify elements like business names and ratings on Yelp, and the platform will handle the extraction.
Yelp website is constantly changing to meet users' expectations, which means the Yelp Reviews API you built might not work as effectively in the future.
Before you start scraping Yelp, it's essential to check their robots.txt file. This file tells web crawlers which parts of the site can be accessed and which are off-limits. By following the directives in this file, you can avoid scraping pages that Yelp doesn't want automated access to. For example, it might specify that you shouldn't scrape pages only for logged-in users.
When making requests to Yelp's servers, using a legitimate user-agent string is crucial. This string identifies the browser or device performing the request. When a user-agent string mimics the appearance of a legitimate browser, it is less likely to be recognized as a bot. Avoid using the default user agent provided by scraping libraries, as they are often well-known and can quickly be flagged by Yelp's security systems.
Implement request throttling to avoid overwhelming Yelp's servers with too many requests in a short period of time. This means adding delays between each request to simulate human browsing behavior. You can do this using sleep functions in your code. For example, you might wait a few seconds between each request to give Yelp's servers a break and reduce the likelihood of being flagged as suspicious activity.
import time
import requests
def make_request(url):
# Mimic a real browser's user-agent
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
if response.status_code == 200:
# Process the response
pass
else:
# Handle errors or blocks
pass
# Wait for 2 to 5 seconds before the next request
time.sleep(2 + random.random() * 3)
# Example usage
make_request('https://www.yelp.com/biz/some-business')
Use proxy servers to cycle your IP address and lower your risk of getting blacklisted if you are sending out a lot of queries. An Example of Python Using Proxies:
import requests
proxies = {
'http': 'http://your_proxy_address:port',
'https': 'https://your_proxy_address:port',
}
response = requests.get('https://www.yelp.com/biz/some-business', proxies=proxies)
Yelp could ask for a CAPTCHA to make sure you're not a robot. It can be difficult to handle CAPTCHAs automatically, and you might need to use outside services.
Use a headless browser such as Puppeteer or Selenium if you need to handle complicated interactions or run JavaScript. Examples of Python Selenium:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
driver = webdriver.Chrome(options=options)
driver.get('https://www.yelp.com/biz/some-business')
# Process the page
driver.quit()
It's important to realize that scraping Yelp might be against their terms of service. Always act morally and think about the consequences of your actions on the law.
Verify whether Yelp provides a suitable official API for your purposes. The most dependable and lawful method of gaining access to their data is via the Yelp restaurant API.
Yelp reviews API and data scraper could provide insightful information for both companies and researchers. In this tutorial, we'll go over how to ethically and successfully scrape Yelp reviews using Python.
The code parses HTML using lxml and manages HTTP requests using Python requests.
Since requests and lxml are external Python libraries, you will need to use pip to install them individually. This code may be used to install requests and lxml.
pip install lxml requests
To obtain these facts, the code will scrape Yelp's search results page.
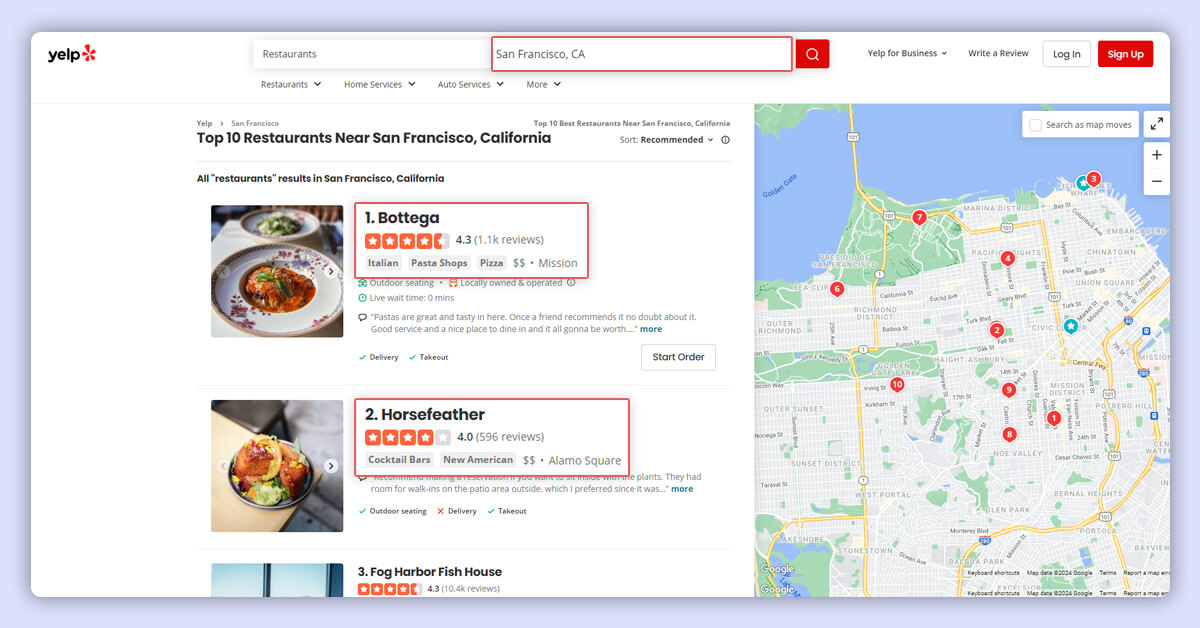
In the JSON data found within a script tag on the search results page, you'll discover all these details. You won't need to navigate through individual data points using XPaths.
Additionally, the code will make HTTPS requests to each business listing's URL extracted earlier and gather further details. It utilizes XPath syntax to pinpoint and extract these additional details, such as:
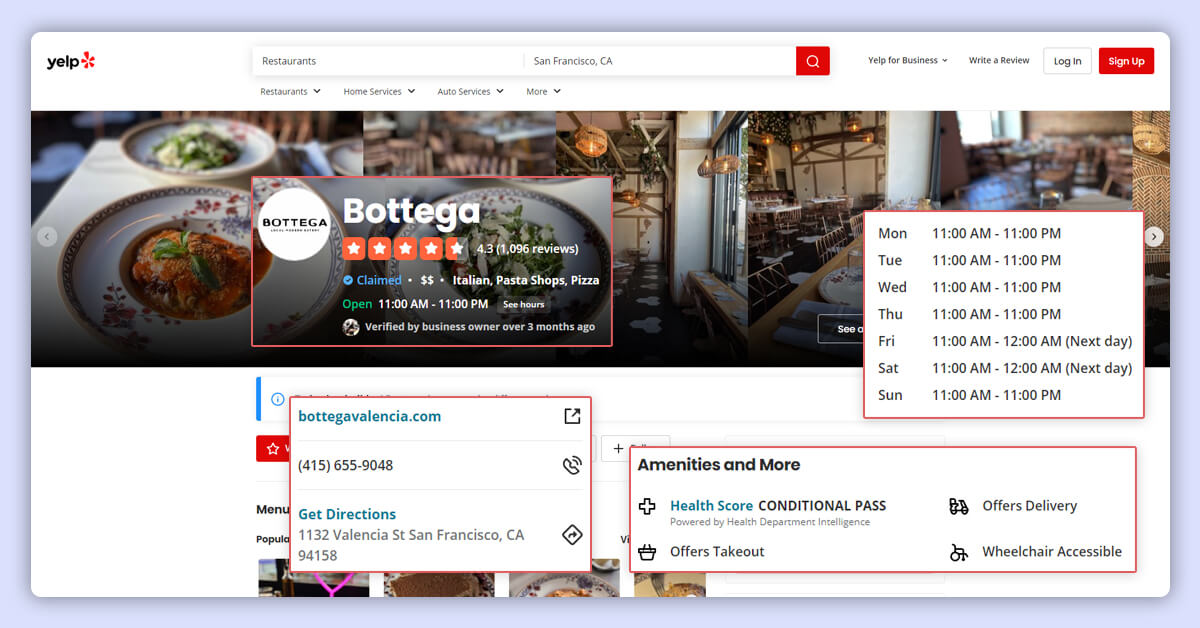
To scrape Yelp reviews using Python, begin by importing the required libraries. The core libraries needed for scraping Yelp data are requests and lxml. Other packages imported include JSON, argparse, urllib.parse, re, and unicodecsv.
from lxml import html
import unicodecsv as csv
import requests
import argparse
import json
import re
import urllib.parse
In this code, you will define two functions: parse() and parseBusiness().
HTTP requests are sent to the search results page.
interprets answers and pulls out business listings
returns objects made from the scraped data.
Parse() uses a header to submit requests to Yelp.com in an attempt to seem like a real user. It sends many HTTP requests in a loop until it receives the status code 200.
headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,'
'*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-GB;q=0.9,en-US;q=0.8,en;q=0.7',
'dpr': '1',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}
success = False
for _ in range(10):
response = requests.get(url, verify=False, headers=headers)
if response.status_code == 200:
success = True
break
else:
print("Response received: %s. Retrying : %s"%(response.status_code, url))
success = False
After receiving the answer, use html.fromstring() to parse it.
parser = html.fromstring(response.text)
The parsed object's JSON contents may now be extracted. After extracting it, you will also process the data by eliminating extraneous characters and spaces.
raw_json = parser.xpath("//script[contains(@data-hypernova-key,'yelpfrontend')]//text()")
cleaned_json = raw_json[0].replace('', '').strip()
The code then extracts the search results after parsing the JSON data with json.loads().
json_loaded = json.loads(cleaned_json)
search_results = json_loaded['legacyProps']['searchAppProps']['searchPageProps']['mainContentComponentsListProps']
After that, you can use get() to cycle over the search results and collect the necessary data.
for results in search_results:
# Ad pages doesn't have this key.
result = results.get('searchResultBusiness')
if result:
is_ad = result.get('isAd')
price_range = result.get('priceRange')
position = result.get('ranking')
name = result.get('name')
ratings = result.get('rating')
reviews = result.get('reviewCount')
category_list = result.get('categories')
url = "https://www.yelp.com"+result.get('businessUrl')
Then, the function
category = []
for categories in category_list:
category.append(categories['title'])
business_category = ','.join(category)
# Filtering out ads
if not(is_ad):
data = {
'business_name': name,
'rank': position,
'review_count': reviews,
'categories': business_category,
'rating': ratings,
'price_range': price_range,
'url': url
}
scraped_data.append(data)
return scraped_data
parseBusiness()
Details are taken from the companies that parse() has extracted using the parseBusiness() method.
The function parses the response after sending an HTTP request to the Yelp business page's URL. But this time, XPaths will be used.
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36'}
response = requests.get(url, headers=headers, verify=False).text
parser = html.fromstring(response)
XPaths can be understood by looking at the source code. Right-click on the webpage to examine it. Take a look at the pricing range code, for instance.
$$
A text enclosed in a span element is the price range. Thus, its XPath can be written as
//span[@class=' css-14r9eb']/text()
In the same manner, you may locate every XPath and retrieve the associated data.
raw_name = parser.xpath("//h1//text()")
raw_claimed = parser.xpath("//span[@class=' css-1luukq']//text()")[1] if parser.xpath("//span[@class=' css-1luukq']//text()") else None
raw_reviews = parser.xpath("//span[@class=' css-1x9ee72']//text()")
raw_category = parser.xpath('//span[@class=" css-1xfc281"]//text()')
hours_table = parser.xpath("//table[contains(@class,'hours-table')]//tr")
details_table = parser.xpath("//span[@class=' css-1p9ibgf']/text()")
raw_map_link = parser.xpath("//a[@class='css-1inzsq1']/div/img/@src")
raw_phone = parser.xpath("//p[@class=' css-1p9ibgf']/text()")
raw_address = parser.xpath("//p[@class=' css-qyp8bo']/text()")
raw_wbsite_link = parser.xpath("//p/following-sibling::p/a/@href")
raw_price_range = parser.xpath("//span[@class=' css-14r9eb']/text()")[0] if parser.xpath("//span[@class=' css-14r9eb']/text()") else None
raw_ratings = parser.xpath("//span[@class=' css-1fdy0l5']/text()")[0] if parser.xpath("//span[@class=' css-1fdy0l5']/text()") else None
Next, you can remove any excess spaces from each piece of data.
name = ''.join(raw_name).strip()
phone = ''.join(raw_phone).strip()
address = ' '.join(' '.join(raw_address).split())
price_range = ''.join(raw_price_range).strip() if raw_price_range else None
claimed_status = ''.join(raw_claimed).strip() if raw_claimed else None
reviews = ''.join(raw_reviews).strip()
category = ' '.join(raw_category)
cleaned_ratings = ''.join(raw_ratings).strip() if raw_ratings else None
But to discover the working hours, you have to go through the hours table again.
working_hours = []
for hours in hours_table:
if hours.xpath(".//p//text()"):
day = hours.xpath(".//p//text()")[0]
timing = hours.xpath(".//p//text()")[1]
working_hours.append({day:timing})
The website URL of the company will be embedded inside another link; thus, you will need to use urllib.parse and regular expressions to decode it.
if raw_wbsite_link:
decoded_raw_website_link = urllib.parse.unquote(raw_wbsite_link[0])
print(decoded_raw_website_link)
website = re.findall("biz_redir\?url=(.*)&website_link",decoded_raw_website_link)[0]
else:
website = ''
Likewise, to obtain the longitude and latitude of the company location, regular expressions are needed.
if raw_map_link:
decoded_map_url = urllib.parse.unquote(raw_map_link[0])
if re.findall("center=([+-]?\d+.\d+,[+-]?\d+\.\d+)",decoded_map_url):
map_coordinates = re.findall("center=([+-]?\d+.\d+,[+-]?\d+\.\d+)",decoded_map_url)[0].split(',')
latitude = map_coordinates[0]
longitude = map_coordinates[1]
else:
latitude = ''
longitude = ''
else:
latitude = ''
longitude = ''
Ultimately, you will attach all of the gathered business facts to an array that the method will return by saving them to a dict.
data={'working_hours':working_hours,
'info':info,
'name':name,
'phone':phone,
'ratings':ratings,
'address':address,
'price_range':price_range,
'claimed_status':claimed_status,
'reviews':reviews,
'category':category,
'website':website,
'latitude':latitude,
'longitude':longitude,
'url':url
}
return data
Next,
configure argparse so that it will take the zip code and command-line search terms.
argparser = argparse.ArgumentParser()
argparser.add_argument('place', help='Location/ Address/ zip code')
search_query_help = """Available search queries are:\n
Restaurants,\n
Breakfast & Brunch,\n
Coffee & Tea,\n
Delivery,
Reservations"""
argparser.add_argument('search_query', help=search_query_help)
args = argparser.parse_args()
place = args.place
search_query = args.search_query
call parse()
yelp_url = "https://www.yelp.com/search?find_desc=%s&find_loc=%s" % (search_query,place)
print ("Retrieving :", yelp_url)
#Calling the parse function
scraped_data = parse(yelp_url)
To save the data to a CSV file, use DictWriter() and write:
1. the CSV file's header using writeheader()
2. Using a loop, writerow() for each row
#writing the data
with open("scraped_yelp_results_for_%s_in_%s.csv" % (search_query,place), "wb") as fp:
fieldnames = ['rank', 'business_name', 'review_count', 'categories', 'rating', 'price_range', 'url']
writer = csv.DictWriter(fp, fieldnames=fieldnames, quoting=csv.QUOTE_ALL)
writer.writeheader()
if scraped_data:
print ("Writing data to output file")
for data in scraped_data:
writer.writerow(data)
Run parseBusiness() repeatedly, exporting the details to a JSON file
for data in scraped_data:
bizData = parseBusiness(data.get('url'))
yelp_id = data.get('url').split('/')[-1].split('?')[0]
print("extracted "+yelp_id)
with open(yelp_id+".json",'w') as fp:
json.dump(bizData,fp,indent=4)
This is the Yelp data that was extracted.
This code can collect data from Yelp for now, but there are a couple of things to keep in mind. Yelp marketplace might change how it organizes its data in the future, so you'll need to tweak this code if that happens.
Also, if you're planning to scrape Yelp reviews with the Yelp restaurant API, you might run into some roadblocks. You might need to use more advanced methods, like rotating proxies, to get around Yelp's anti-scraping defenses.
With the help of Python scripts, it is possible to gather a large amount of useful and comprehensive customer feedback from the Yelp website, which can be incredibly helpful for a company or a researcher. It will also be very useful for business as it can help in decision making, selling campaigns, and modifications to products. However, it is also important not to overload Yelp with too many requests at one go since this is counterproductive. As a result, a great deal of insightful information may be gathered that may serve to illustrate both how using Yelp reviews to achieve company success is useful and how to scrape Yelp reviews with Python in an ethical and responsible manner. Also, if you are planning to scrape large and many quantities of information, then you can actually buy their service from Reviewgators. They provide tailored scraping Yelp review solutions as well as data extraction outsourcing, including server-side automation.
Feel free to reach us if you need any assistance.
We’re always ready to help as well as answer all your queries. We are looking forward to hearing from you!
Call Us On
Email Us
Address
10685-B Hazelhurst Dr. # 25582 Houston,TX 77043 USA
ReviewGators provides the Best Online Reviews API to help you access well-structured data of customers’ feedbacks.
© 2012 - 2025 ReviewGators, All rights reserved.
