Blog / Maximize your market research with our guide to scraping Amazon reviews. Get expert tips on collecting and analyzing reviews to boost your business insights.
03 July 2024

Amazon, the global internet-based store or electronic commerce firm, has revolutionized the way it sells or purchases over the internet. Thus, according to the statistical data, Amazon's net sales reached almost $575 billion in 2023 worldwide.
Retailing is Amazon's most common source of income, and it mainly comprises the e-retailing of numerous products. It also makes money from third party sellers, subscriptions to services such as Amazon Prime, and AWS cloud services. About 60% of products sold on the Amazon are from the third party sellers who sell on behalf of themselves and through the Amazon marketplace. In return, these sellers benefit from Amazon in that the company assists in picking up, packing, shipping, and handling orders in its Fulfilled-by-Amazon (FBA) provision. About half of the units bought in most of the Amazon markets are controlled by this service.
Amazon review scraping is the technique of mechanically obtaining customer reviews from the Amazon website. This is done using special software or scripts that can browse through product pages, find the review sections, and gather the review information. This data includes the review text, star ratings, reviewer names, and review dates. Once collected, the data is organized so businesses can analyze it quickly.
Businesses scrape Amazon reviews to understand what customers think about their products. By looking at many reviews, they can find out what customers like or dislike about their products. To successfully scrape reviews, businesses must invest in advanced tools and continuously update them to keep up with these changes.

Scraping Amazon reviews can be beneficial for various reasons, particularly for businesses, researchers, and consumers.
Reviews provide a rich source of unfiltered customer opinions. These reviews can be used by the businesses to determine what the customers feel in as much detail as is possible. A considerable advantage of reading reviews is that companies can find out which features their clients appreciate and what aspects need enhancements. This data may be particularly useful for product elaboration and advertising campaigns.
Customer reviews are helpful for practical competition analysis since they reveal how customers consider similar products from other businesses. Competitors can also use this to their advantage to know their strengths and weaknesses, hence helping a company to see its unique selling point. People may give reviews in the course of using the product and this can be helpful in determining if there is something new as per the customers or how the customers have decided to use the product different from what it is intended for. This kind of foresight can be extremely useful in the context of thriving to be ahead of the competition in the sphere of products and marketing.
Studying reviews enables firms to know the sort of words consumers apply when defining their goods and characteristics. This enables them to exploit these words when placing their marketing campaigns to enhance precise ad placement and appropriate customer base attraction. Some aspects that may go down well with customers may be brought out by the reviews. Companies can use this information to improve their product descriptions, focusing on the main parameters for sales promotion in the lists.
Opinion can reveal problems customers of a certain product encounter on an everyday basis. It, therefore, follows that businesses that address these problems enhance their ability to produce better products, thereby serving the needs of the consumers well. It is because organizations can easily counter all negative comments concerning their business, ensuring that the public knows that they are willing to work towards satisfying customers. Also, having a list of positive feedback is always good because it can be used as a reference to encourage other customers to try the establishments being rewarded.
For this tutorial, you will need Python 3.8 or newer installed, along with three essential packages: Requests, Pandas, Beautiful Soup, and lxml.
Next, import all the necessary libraries and create a header.
import requests
from bs4 import BeautifulSoup
import pandas as pd
custom_headers = {
"accept-language": "en-GB,en;q=0.9",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.1 Safari/605.1.15",
}
In order to avoid being prevented while collecting Amazon reviews, bespoke header implementation is essential.
When you're prepared to begin scraping, gather every review object and take out the necessary data from it. To extract every product review, you will need to locate a CSS selector and then utilise the.select function.
To find the Amazon reviews, utilise this selector
div.review
The code to gather them is as follows
review_elements = soup.select("div.review")
You will then have a variety of all the reviews to go through and get the necessary data from.
To begin iterating, you'll need a for loop and an array to which you can add the processed reviews
scraped_reviews = []
for review in review_elements:
Name of author
The author's name is listed first in our list. To choose the name, use the CSS selector provided here:
span.a-profile-name
Additionally, you can use the following snippet to gather the names in plain text
r_author_element = review.select_one("span.a-profile-name")
r_author = r_author_element.text if r_author_element else None
Review rating
The review rating is the next item to be extracted. You may find it by using the following CSS
i.review-rating
There is some unnecessary additional text in the rating string, so let's eliminate it
r_rating_element = review.select_one("i.review-rating")
r_rating = r_rating_element.text.replace("out of 5 stars", "") if r_rating_element else None
Headline
Use this selection to obtain the review's title
a.review-title
As stated below, you must provide the gap in order to obtain the real title text.
r_title_element = review.select_one("a.review-title")
r_title_span_element = r_title_element.select_one("span:not([class])") if r_title_element else None
r_title = r_title_span_element.text if r_title_span_element else None
Review the text
The following selection will allow you to locate the review text itself:
span.review-text
After that, you may extract relevant language from Amazon reviews:
r_content_element = review.select_one("span.review-text")
r_content = r_content_element.text if r_content_element else None
Date
The date is an additional item to retrieve from the review. The CSS selector that follows can be used to find it:
span.review-date
The code to retrieve the date value from the object is as follows:
r_date_element = review.select_one("span.review-date")
r_date = r_date_element.text if r_date_element else None
Confirmation
You may also see if the review has been confirmed or not. This selector may be used to retrieve the object containing this data:
span.a-size-mini
And extracted with the help of the subsequent code:
r_verified_element = review.select_one("span.a-size-mini")
r_verified = r_verified_element.text if r_verified_element else None
Photos
Lastly, you can use this selection to obtain the URLs of any new images that are added to the review:
img.review-image-tile
After that, use the following code to extract them:
r_image_element = review.select_one("img.review-image-tile")
r_image = r_image_element.attrs["src"] if r_image_element else None
Now that you've acquired all of this data, combine it into one object. Next, add that item to the collection of product reviews you have built before initiating our for loop:
r = {
"author": r_author,
"rating": r_rating,
"title": r_title,
"content": r_content,
"date": r_date,
"verified": r_verified,
"image_url": r_image
}
scraped_reviews.append(r)
Data exporting
The final step is to export the data to a file once all of the data has been scraped. With the following code, you can export the data in CSV format:
search_url = "https://www.amazon.com/BERIBES-Cancelling-Transparent-Soft-Earpads-Charging-Black/product-reviews/B0CDC4X65Q/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews"
soup = get_soup(search_url)
reviews = get_reviews(soup)
df = pd.DataFrame(data=reviews)
df.to_csv("amz.csv")
The file amz.csv contains your data once the script has run:
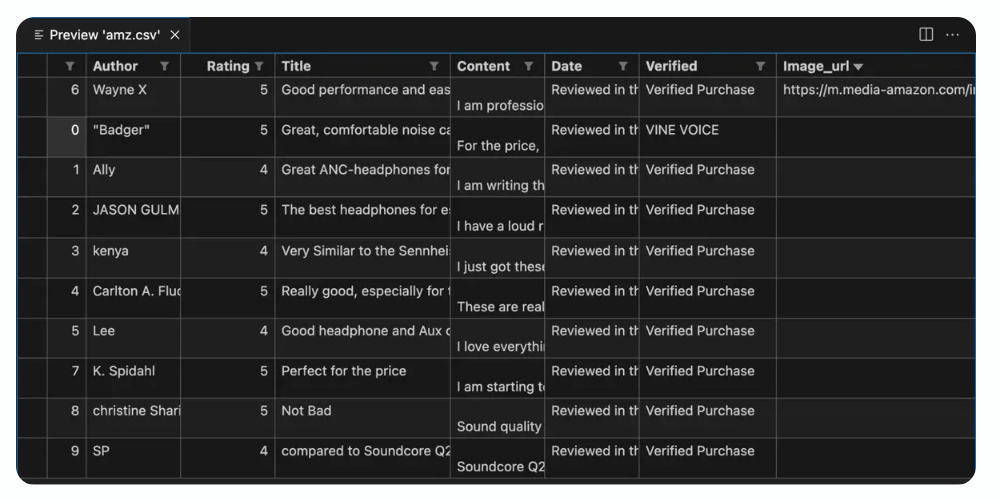
This is the full script:


Scraping Amazon reviews presents several challenges, including technical, ethical, and legal hurdles. These challenges make scraping Amazon review data a complex task.
Amazon monitors the activity of data scrapers. They can analyze things like how fast you're sending requests and what type of device you're using (browser vs. scraper program). If you seem suspicious, they might:
Throttle your requests: Slow you down to make scraping take a long time.
Throw CAPTCHAs at you: Those annoying puzzles designed to stop bots.
Block your IP address: Completely restrict you for a while.
Amazon's website isn't set in stone. They constantly update layouts and how information is displayed. This can break your scraper if it relies on finding data in specific locations on the page. Amazon might be testing new layouts or features on a small group of users. If you hit one of these test pages, your scraper might be unable to handle the unexpected structure.
A single product listing can have many variations, like size, color, or features. Reviews might be grouped for all variations, making it hard to separate reviews for specific versions you're interested in. What you see on Amazon depends on your location. Reviews might be specific to a particular region, and scraping reviews might require considering these variations.
Amazon might only show reviews for products available in your region. Scraping reviews might require setting up geo-restrictions and connections that appear to be from different locations.
Designing a scraper that can address all these issues requires certain programming skills and knowledge of how to scrape the web. Whereas scraping a handful of reviews might be easily doable, it is quite another story when one wants to scrape hundreds or thousands of reviews.
Reviews might be in various languages, depending on the region. If you only handle English reviews, you'd miss out on valuable data in other languages.
Therefore, here are a few quick solutions that can effectively help to scrape Amazon reviews. One of the key approaches is employing sophisticated instruments that replicate how a person interacts with the web. For instance, the IP addresses can be rotated with proxies so that the scraper is not caught and, hence, banned. This means that every request appears to originate from a different location, and, as you know, real people shop at Amazon from various geographical locations. Furthermore, sending requests at odd times, not in the set time intervals, is also good for preventing Amazon from blocking scraping since the scraping does not follow any specific pattern.
To do so, businesses update the scripts, as mentioned earlier, to reflect such alterations so that their scraping tools are not rendered ineffective. Moreover, accessing Amazon's web services for price scraping may be partially prevented by the security measures implemented by the company, and the usage of CAPTCHA-solving services can help in this regard. CAPTCHAs are those little tests like you sometimes have to right if the site does not want you to scrape its content because you seem like a bot, having a system to deal with CAPTCHAs can hence maintain the stability of scraping.
Businesses can also adopt other websites that provide web scraping services specializing in scraping information from Amazon. These services possess the capacity and capability to deal with the probable challenges of scraping big data. They are very discreet in their work, hence, they can easily escape identification and can deliver a clean data set well arranged for analysis. It is noteworthy that by paying for the scraping services, the enterprises can free up their time and efforts to refine and maintain their own scraping instruments.
However, it is also necessary to look into legal and ethical aspects with technical solutions proposed for the general use of businesses. At times, scraping goes against the terms of the website's service agreement; hence, an essential factor while scraping is legal compliance.
Scraping Amazon reviews can be extremely helpful for businesses since the collected data reveals the customers’ experience, product ratings, and tendencies. This information assists them in making better decisions on the kind of products to bring to the market, the satisfaction of customers, and the ability to outcompete other businesses. Companies can minimize the risk of legal issues by using professional services that adhere to these rules while still gaining valuable insights from Amazon reviews. This allows them to focus on improving their products and strategies based on the data collected. Outsourcing to ReviewGators to scrape Amazon reviews is crucial due to the technical complexity and legal intricacies involved. We also ensure data quality by filtering out fake reviews and maintaining the scraper to adapt to frequent changes in Amazon's HTML structure.
Feel free to reach us if you need any assistance.
We’re always ready to help as well as answer all your queries. We are looking forward to hearing from you!
Call Us On
Email Us
Address
10685-B Hazelhurst Dr. # 25582 Houston,TX 77043 USA
ReviewGators provides the Best Online Reviews API to help you access well-structured data of customers’ feedbacks.
© 2012 - 2026 ReviewGators, All rights reserved.
Disclaimer : Reviewgators.com only extracts or scrape the information or the data that is publicly available as well as does not scrape personal or identity-related information.
