Blog / Discover how to scrape Amazon product reviews behind a login with our expert advice. Learn best practices & essential tools to access valuable data insights.
31 May 2024

Amazon is a global premier online shopping site with many products for sale and an almost limitless number of customer feedback. For businessmen and researchers, it can be like an encyclopedia with essential information to make the right decision when investing in a particular item or creating a product line.
As sellers fill up online stores with products, customers can be picky and easily switch between brands and items until they find exactly what they're looking for. What’s also interesting is that they are not very discreet about it; they will create posts to share their experiences with certain products and, quite often, write a review post to help people decide what to purchase next. This enables the clients to offer their views about the products that companies deal in and this will be an added advantage in that companies will improve their products depending on what the clients are saying. This blog will focus even deeper on how scraping is accomplished on product review scraping in one of the largest retail e-commerce websites, Amazon.
Web scraping amazon reviews, therefore, entails the process of automatically scraping and gathering reviews from the product page of Amazon using web scrape tools. This tool crawls through the code of the website, scans over the reviews, and extracts some of the pertinent information, such as the author of the review, the rating given by the author, the comment, and the date of entry of that comment. Not to mention it is very efficient to get a lot of opinions at once in one spot. Nonetheless, it’s important to understand that this tool must be used correctly and adhere to the guidelines posted by Amazon and pertinent laws to prevent any problems with the law and account termination.
Amazon Reviews scraping using Python involves the process of making requests to the review pages of the item, analyzing the structure of the page, and then extracting data such as the name of the reviewer, star ratings, and comments for that particular item. It is similar to training a computer to live within the Amazon website or interface and obtain review data apart from the manual input. In general, the given process is helpful in order to scrape Amazon product reviews to gain more data overall in less time.
Amazon review scraping involves using automated tools to collect customer reviews from Amazon product pages. This practice offers several benefits that can help businesses in various ways. Here’s a detailed explanation of Amazon product review scraping to boost business operations:
Web scraping amazon reviews often mention specific problems or suggestions for products. Scraping these reviews lets businesses see common issues that need fixing. For instance, if several reviews mention that a blender’s motor is weak, the company can focus on making it stronger in the upcoming version.
By also scraping reviews of competitors' products, businesses can learn what their competitors are doing well or poorly. Businesses can improve their own products by taking note of the mistakes made by competitors and applying those winning traits to their own products.
Analyzing the emotions and opinions expressed in reviews helps businesses understand how customers feel about their products. Positive sentiments can indicate what’s working well, while negative sentiments can signal areas that need improvement. This helps in quickly addressing any issues and maintaining customer satisfaction.
Review data shows what problems customers frequently face. This information helps businesses provide better customer service by anticipating issues and creating improved how-to manuals. For example, if many reviews mention difficulties with assembly, the company can create clearer instructions or instructional videos.
Knowing what customers appreciate about a product helps businesses create better marketing messages by scraping Amazon reviews. For example, if reviews highlight that a product is particularly useful for families, the marketing team can emphasize this in their advertising campaigns.
Insights from Product Review Scraping can improve product descriptions by highlighting features and products that customers prefer. Dealing with negative reviews openly shows potential customers that the company appreciates their feedback, which might increase sales and build confidence.
Insights from Product Review Scraping can improve product descriptions by highlighting features and products that customers prefer. Dealing with negative reviews openly shows potential customers that the company appreciates their feedback, which might increase sales and build confidence.
Insights from Product Review Scraping can improve product descriptions by highlighting features and products that customers prefer. Dealing with negative reviews openly shows potential customers that the company appreciates their feedback, which might increase sales and build confidence.
Detailed review data provides valuable insights that help businesses make informed decisions. Whether deciding to launch a new product, discontinue a failing one, or enter a new market, review data provides evidence to support these choices.
Automated Amazon review scraping tools can collect vast amounts of review data quickly and efficiently, saving time and resources compared to manual collection. As a result, businesses can focus less on collecting data and more on analyzing it.
By gathering a large number of customer reviews from automated tools that scrape Amazon product reviews, businesses can understand what customers like and dislike about their products. This information helps companies see trends and patterns in customer preferences. For example, if many customers praise a product's durability, the company knows that this is a strong selling point.
When you scrape Amazon product ratings and reviews, you’re essentially extracting large datasets of information about customer satisfaction, market trends, and product quality. But it is not as easy when doing web scraping for Amazon reviews because Amazon follows strict guidelines and safety measures.
For following along with the code examples in this guide, you'll need to set up Python libraries to your computer. Don't worry if you don't have it yet, you just need to head over to the official website of Python and download the latest version (Python v3.5 or newer will work just fine).
Once Python is installed, you'll also need to get two additional tools: The library of undetected_chromedriver and Selenium. So, Selenium will help you interact with the Amazon website, even behind a login, while undetected_chromedriver will ensure that Amazon doesn't flag your automated activity as suspicious.
To keep things neat and tidy, it's best to set up a separate environment for these tools. Open your command prompt or terminal, make new folder (you can name it whatever you like; let's call it "product_reviews" for this guide), and navigate into it. This way, you'll have a clean space to install and work with these dependencies without interfering with other projects on your computer. Let's get started!
mkdir product_reviews
Navigate to the freshly created folder instead of your current directory:
cd product_reviews
Once you're in the product_reviews directory, use the following command to launch virtual environment:
# Create a virtual environment named 'env'
python -m venv env
Enter the name of your desired virtual environment in lieu of "env."
Run this to enable the created virtual environment if you're on Windows:
env\Scripts\activate
You can use this if you're using Linux or MacOS:
source env/bin/activate
You should notice a message indicating that your terminal prompt is executing virtual environment.
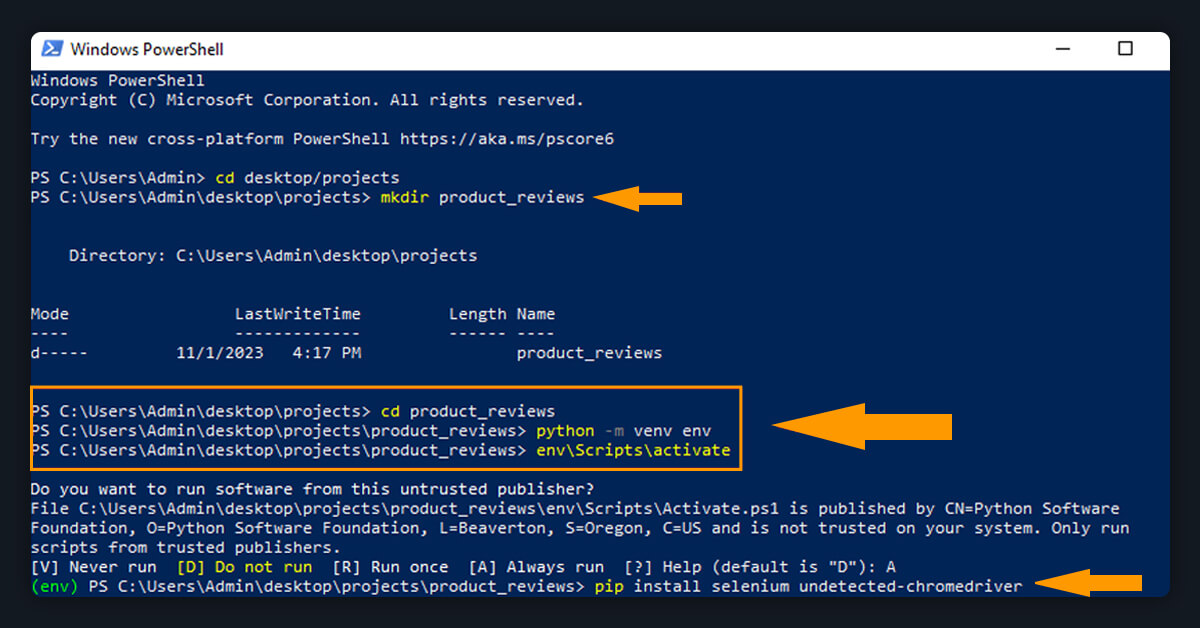
Now run the command mentioned below to install the dependencies:
pip install selenium undetected-chromedriver
A snapshot of the procedure is shown below:
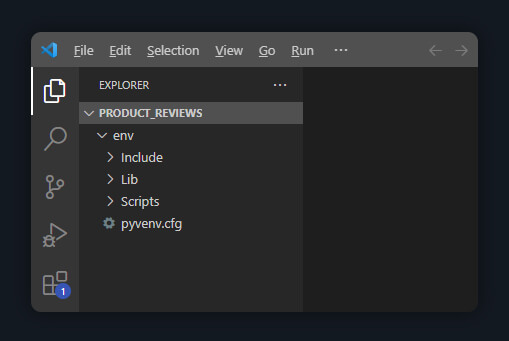
Now, launch the folder to your preferred code editor (VS Code is used in this tutorial). This is how the structure of your library will appear:
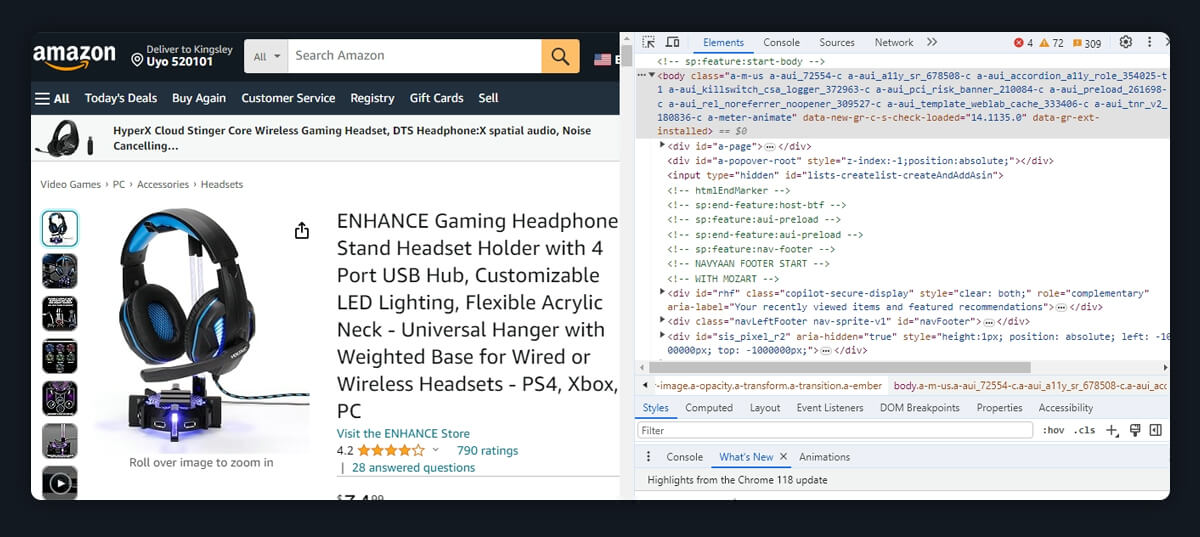
The product web page that you will be scrapping is seen in the image below. You will take the name of the author, the title of the review, and the date from that page.
Make a fresh file called script.py into your project's root folder. The following code sample demonstrates how to launch a WebDriver instance of Chrome, set it up, retrieve the product URL's HTML code, and output received HTML into a terminal. The written code is located in script.py.
Now, you required to Run script as follows using Python file on the appropriate command line (within the currently active virtual infrastructure):
Run Python file to put the code into action:Run Python file to put the code into action:Run Python file to put the code into action:NOTE: Before executing the aforementioned script, make sure to use the updated Google Chrome web browser. If not, an error can appear.
The Amazon website should appear in a terminal with its HTML markup displayed.
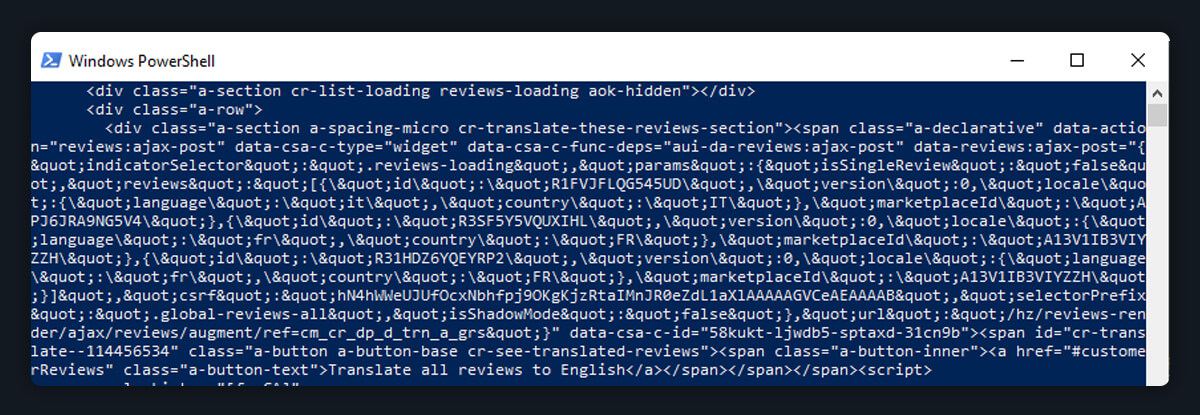
Even while scraping publicly accessible websites is often simple, Some content can't be accessible to you if you are not logged in. The next part will walk you through how to extract pages that need a login by using Selenium.
The password and email pages are the two pages you must navigate in order to log into Amazon.
Getting login page, choosing the required ID for password and email fields, filling in those forms with information, and then clicking on the submit are the steps in the process.
You need to find the URL of Amazon login in your browser in order to start the process. First, log out from your previously opened Amazon account. Next, on amazon.com, select "Sign in". Copy the required URL from address bar once you're on the "log in" page. In the code, it is necessary.
To get the ID from the HTML components, on the login page, you need to right-click on form and select the components tab. Now, Expand HTML markup once you will able to check the ID of the element which contain the button and form.
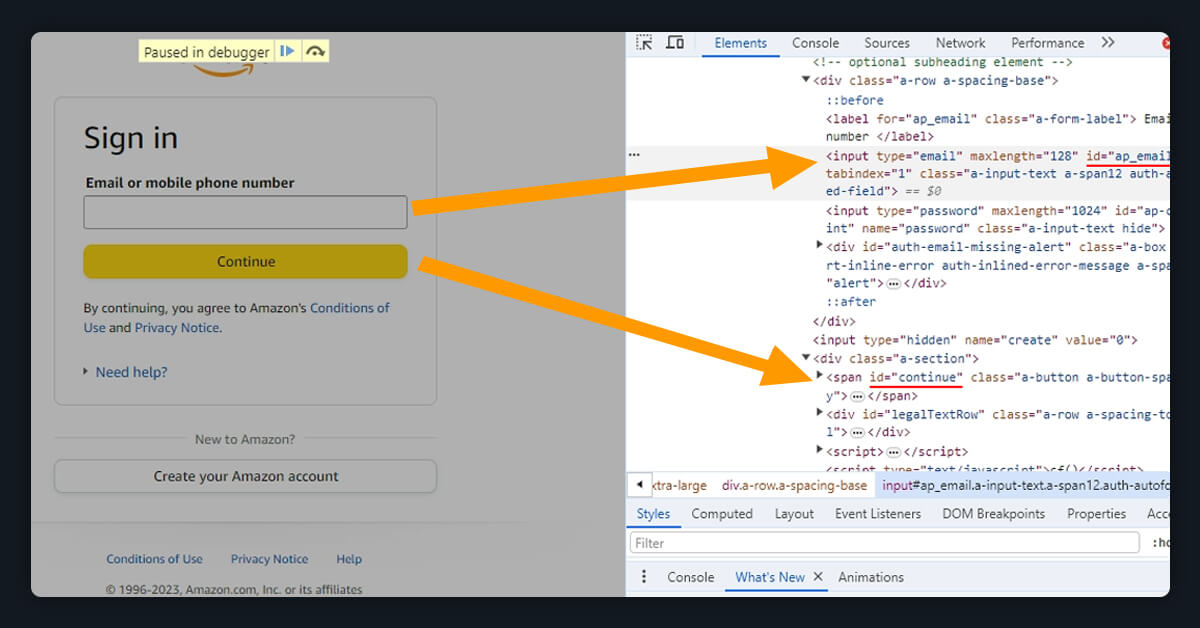
The snippet of the code clearly demonstrates the process of logging in and accessing the elements. The form components that need your email address and password are accessed using Selenium. Next, it clicks the button of submit to send your login credentials. Ultimately, the HTML code is retrieved and printed to the terminal:
import undetected_chromedriver as uc
import time
from selenium.webdriver.common.by import By
chromeOptions = uc.ChromeOptions()
chromeOptions.headless = False
driver = uc.Chrome(use_subprocess=True, options=chromeOptions)
# Replace the Amazon link below with your login URL
driver.get("https://www.amazon.com/ap/signin?openid.pape.max_auth_age=0&openid.return_to=xxxxxxxxxxxx")
time.sleep(5) # Wait for a few seconds to ensure the page loads completely
email = driver.find_element(By.ID, "ap_email")
# Replace the xxx with your Amazon email
email.send_keys("xxxxxxxxx")
driver.find_element(By.ID, "continue").click()
time.sleep(5)
password = driver.find_element(By.ID, "ap_password")
# Replace the xxx with your Amazon password
password.send_keys("xxxxxxxx")
driver.find_element(By.ID, "signInSubmit").click()
time.sleep(10)
# Extract the full HTML of the page and store it in the 'page_html' variable
page_html = driver.page_source
print(page_html)
driver.close() # Close the WebDriver instance
The output from the code above is the same as that from step 2. However, we're now completed logging in process in Amazon this time.
Note: Make sure you have your login information safe before transferring your code into a public repository.
Parse Review Details
Parsing the obtained data will enable you to scrape the necessary information if you just need a portion of it. In order to ID or determine the class of the selected element holding the required detail you need to parse, you must additionally check the HTML throughout the parsing process.
You will be scraping the review contents, review dates, and author names for this lesson. These elements can be found by using the corresponding selectors of CSS. The name of a review author and the class called "a-profile-name" that goes with it are displayed in the image below:
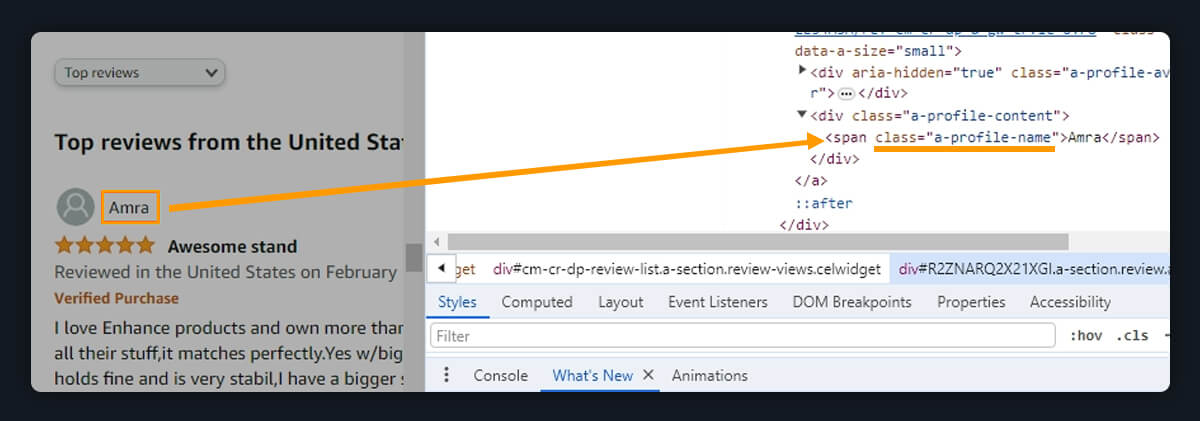
To obtain the class names for the rating and review text and its date, follow the same procedure.
You can check the text content of those three components in your written Python code & output it to console once you know their class names. The following code sample accomplishes this:
import undetected_chromedriver as uc
import time
from selenium.webdriver.common.by import By
chromeOptions = uc.ChromeOptions()
chromeOptions.headless = False
driver = uc.Chrome(use_subprocess=True, options=chromeOptions)
# Replace the Amazon link below with your login URL
driver.get("https://www.amazon.com/ap/signin?openid.pape.max_auth_age=0&openid.return_to=xxxxxxxxxxxx")
time.sleep(5) # Wait for a few seconds to ensure the page loads completely
email = driver.find_element(By.ID, "ap_email")
# Replace the xxx with your Amazon email
email.send_keys("xxxxxxxxx")
driver.find_element(By.ID, "continue").click()
time.sleep(5)
password = driver.find_element(By.ID, "ap_password")
# Replace the xxx with your Amazon password
password.send_keys("xxxxxxxx")
driver.find_element(By.ID, "signInSubmit").click()
time.sleep(10)
# Navigate to the Amazon product page
product_url = "https://www.amazon.com/ENHANCE-Headphone-Customizable-Lighting-Flexible/dp/B07DR59JLP/"
driver.get(product_url)
time.sleep(10) # Wait for a few seconds to ensure the page loads completely
# Locate and extract review elements
review_elements = driver.find_elements(By.CSS_SELECTOR, '.a-section.review')
for review_element in review_elements:
# Extract the author name
author_name = review_element.find_element(By.CLASS_NAME, 'a-profile-name').text
# Extract review text
review_text = review_element.find_element(By.CLASS_NAME, 'review-text').text
# Extract review date
review_date = review_element.find_element(By.CLASS_NAME, 'review-date').text
# Print the extracted information
print("Author: ", author_name)
print("Review: ", review_text)
print("Review Date: ", review_date)
print("\n")
driver.close()
Run Python file to put the code into action:
python script.py
There should only be three pieces of detailed data for each rating and review on the console: the date, the review content, and the author's name. Your final product ought to resemble this:
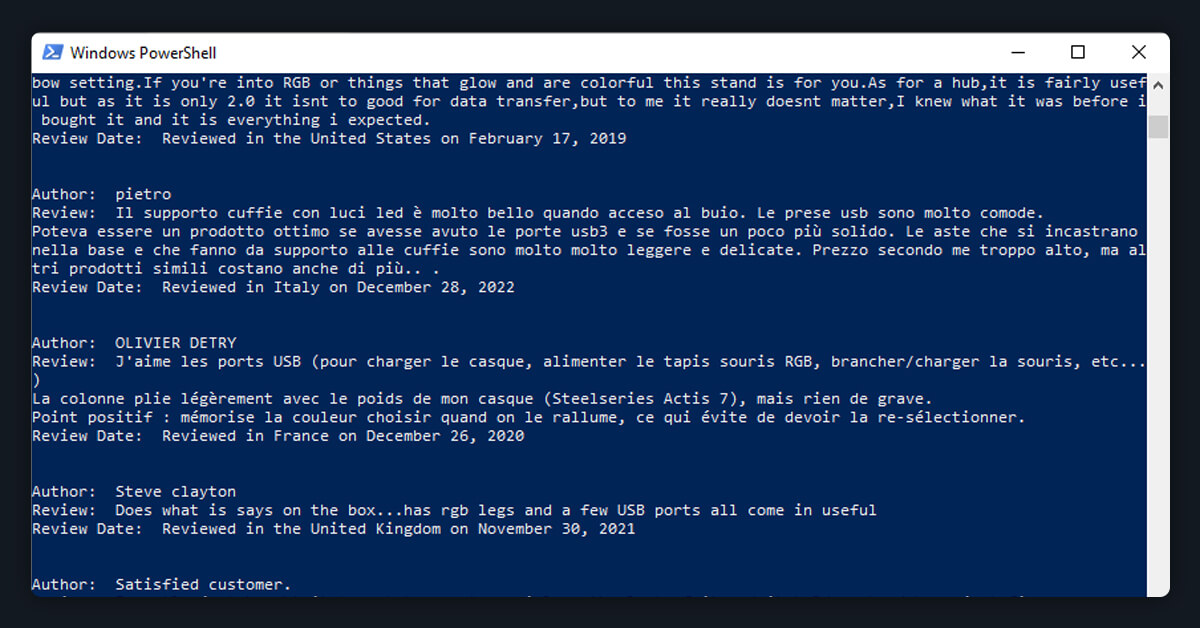
After extracting the data you want, the further process is to display it in an easily shared and analyzed manner. The CSV format, that saves data in the tabular format which is considered your best option. The section that follows covers how to export the ratings and reviews into a CSV file format.
Python has an integrated CSV module that you may use to interact with the CSV file into your script. After importing required module, you need to open a Comma Separated Value file and add a row with the values like "Review Date", "Review," and "Author". Next, create a new row with the author's name, the review content, and the date for each review that was pulled from the product page.
This sample of code demonstrates how to perform this:
import undetected_chromedriver as uc
import time
import csv
from selenium.webdriver.common.by import By
chromeOptions = uc.ChromeOptions()
chromeOptions.headless = False
driver = uc.Chrome(use_subprocess=True, options=chromeOptions)
# Replace the Amazon link below with your login URL
driver.get("https://www.amazon.com/ap/signin?openid.pape.max_auth_age=0&openid.return_to=xxxxxxxxxxxx")
time.sleep(5) # Wait for a few seconds to ensure the page loads completely
email = driver.find_element(By.ID, "ap_email")
# Replace the xxx with your Amazon email
email.send_keys("xxxxxxxxx")
driver.find_element(By.ID, "continue").click()
time.sleep(5)
password = driver.find_element(By.ID, "ap_password")
# Replace the xxx with your Amazon password
password.send_keys("xxxxxxxx")
driver.find_element(By.ID, "signInSubmit").click()
time.sleep(10)
# Navigate to the Amazon product page
product_url = "https://www.amazon.com/ENHANCE-Headphone-Customizable-Lighting-Flexible/dp/B07DR59JLP/"
driver.get(product_url)
time.sleep(10) # Wait for a few seconds to ensure the page loads completely
# Locate and extract review elements
review_elements = driver.find_elements(By.CSS_SELECTOR, '.a-section.review')
csv_filename = 'product_reviews.csv'
with open(csv_filename, 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(['Author', 'Review', 'Review Date'])
for review_element in review_elements:
# Extract the author's name
author_name = review_element.find_element(By.CLASS_NAME, 'a-profile-name').text
# Extract review text
review_text = review_element.find_element(By.CLASS_NAME, 'review-text').text
# Extract review date
review_date = review_element.find_element(By.CLASS_NAME, 'review-date').text
# Print the extracted information
print("Author: ", author_name)
print("Review: ", review_text)
print("Review Date: ", review_date)
print("\n")
csv_writer.writerow([author_name, review_text, review_date])
driver.close()
This code will compile the collected Amazon review data into a CSV file that is organized elegantly. Your final product ought to resemble this:
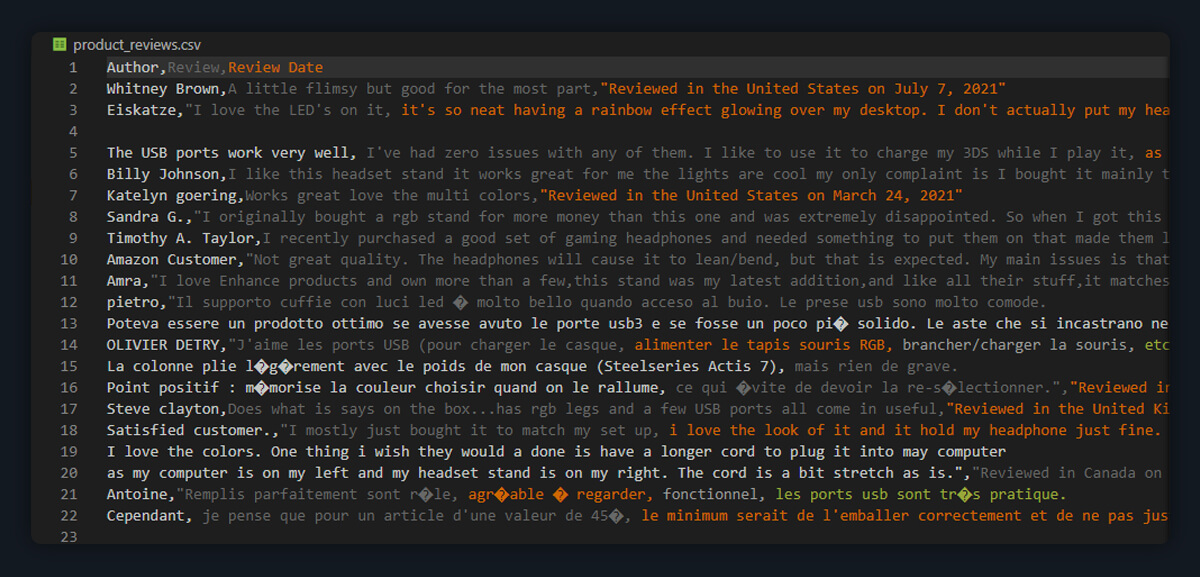
This CSV file is easily shareable, can be imported into a data analysis program, or processed further to gain a more in-depth understanding of the product's marketability.
Scraping Amazon product reviews behind the login can go a long way to help businesses since it gives detailed information on the opinions and experiences of the customer. Using such reviews helps in accessing information and feedback that can not be exposed by social web reviews. It is also useful in analyzing customer’s perspectives, knowing areas of concern and possibly appreciable and depreciable features of a product. It is through this analysis that the various aspects of the business, such as product development, customer relations, and specific marketing models, can effectively direct toward the real outlook of consumers and what they feel about the products or services sold in a particular market.
In addition, web scraping Amazon reviews from behind a login can benefit businesses in that they can get a better picture of the competition. Additionally, by the use of customer feedback, between similar products in the market, it is easy for the business to realize the holes within its market, appreciate performance level as well as recognize trends. By conducting this competitive analysis, business organizations gain insight into potential evolutions within the market or industries they operate in and develop appropriate products/ services accordingly. Therefore, combining detailed review data is beneficial in influencing product development, increasing consumer satisfaction, and advancing organizational benefit in a competitive environment.
Feel free to reach us if you need any assistance.
We’re always ready to help as well as answer all your queries. We are looking forward to hearing from you!
Call Us On
Email Us
Address
10685-B Hazelhurst Dr. # 25582 Houston,TX 77043 USA
ReviewGators provides the Best Online Reviews API to help you access well-structured data of customers’ feedbacks.
© 2012 - 2025 ReviewGators, All rights reserved.
