Blog / How Web Scraping is Used for Analyzing Yelp Restaurants Data
13 April 2022

Whenever you want to go for a pleasant lunch in the restaurants, you generally prefer to check for the hotels in your region that have the top ratings. Yelp is a website that assists you in filtering restaurants based on user ratings and reviews. The User Interface of Yelp makes it simple to filter and search results based on a person's desired location, food preference, and rating.
Here, Yelp restaurant API is used to scrape Yelp restaurant data results for in New Jersey, Kearny, and then filter out the major 10 highly rated hotels and plotted the histogram to see how restaurants are distributed based on the ratings.
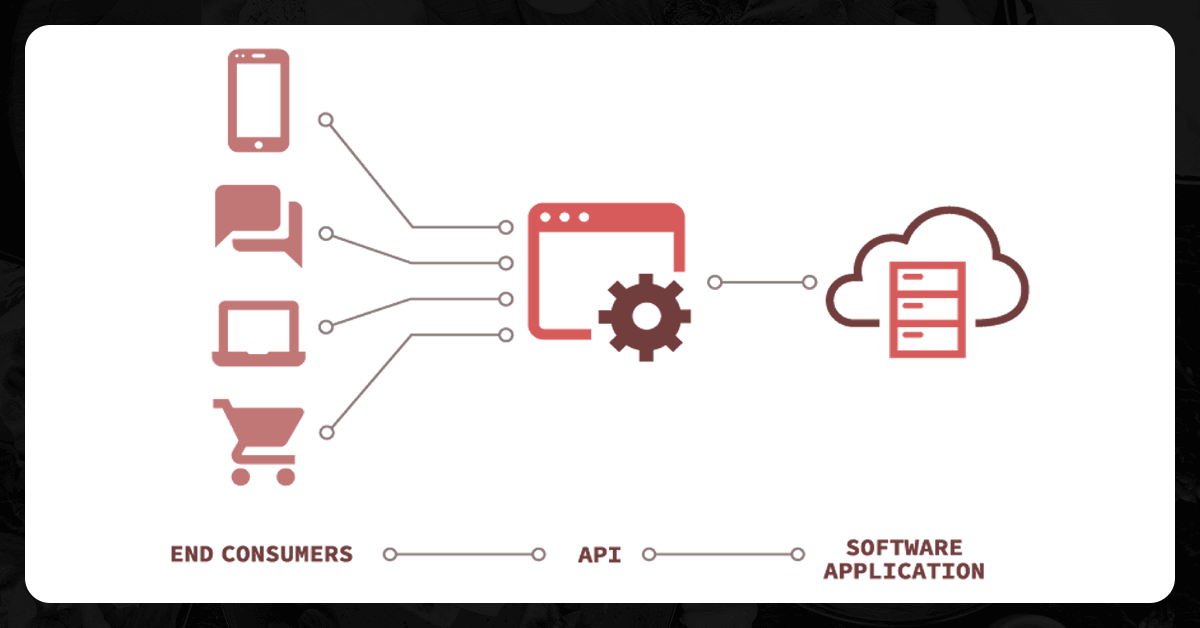
There are numerous definitions of API and how it is useful for the websites. API is an interface which provides the medium of communication among two servers. This software allows two apps to interact with one another through the use of an interface. The term "API" refers to the service provider that accepts request in an HTTP format and delivers to another server. The server responds to API and gives back.
APIs are used to retrieve data, communicate with other software components, and so on. The data in an API could be in either XML or JSON format. Obtaining data in API, you must generate the key for an API. The API key is required for retrieving data through an API because it assists user authentication. And the key also assists us in recognizing the user. Never share the key with anyone. The access should be given to user and server only.
Let us look at what Web Scraping services is and how we can do it. Web scraping is the technique of gathering web data and applying it for data analysis to get usable information.
Yelp's Fusion API is used:
GET https://docs.developer.yelp.com/docs/fusion-intro
GET request can be made using the URL mentioned above, it is the HTTP request which will allow to retrieve data from Yelp's search API for restaurants. Now API is known to you so, let us create an API key that will allow you to access the data. The form provided below must be completed to generate the API key, which will result in client ID with the API key.

Now when we have the key, let us set up an environment and execute web scraping. Here Google Collab is used, which is a free open-source IDE permits us to develop and run Python code, similar to the Jupyter. The primary step is to build up the libraries, which include the following:
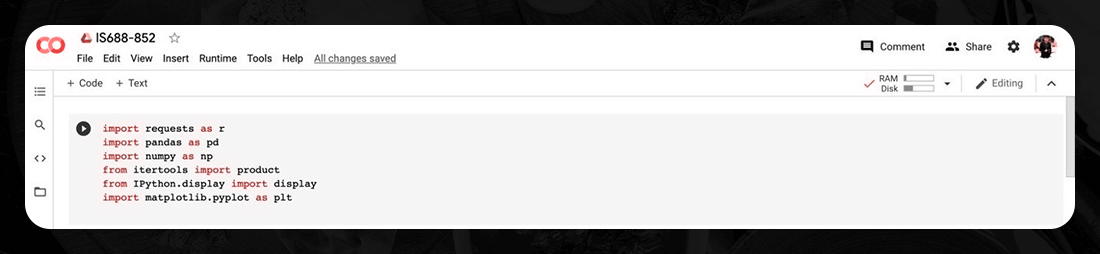
Let's look at the functions that each library offers:
Following the installation of the libraries, the request of HTTP is made to URL and saved the database in JSON format. The data is examined after getting it to see if there were any duplicate values, null values, typos, or missing values. If any values are present in the data, data cleaning is performed to remove any of those redundant parts of information, because they are useless in data analysis. You can continue because your data from Yelp's business search API did not contain any of these redundant values. The response that is obtained by running a request in JSON format is shown below.

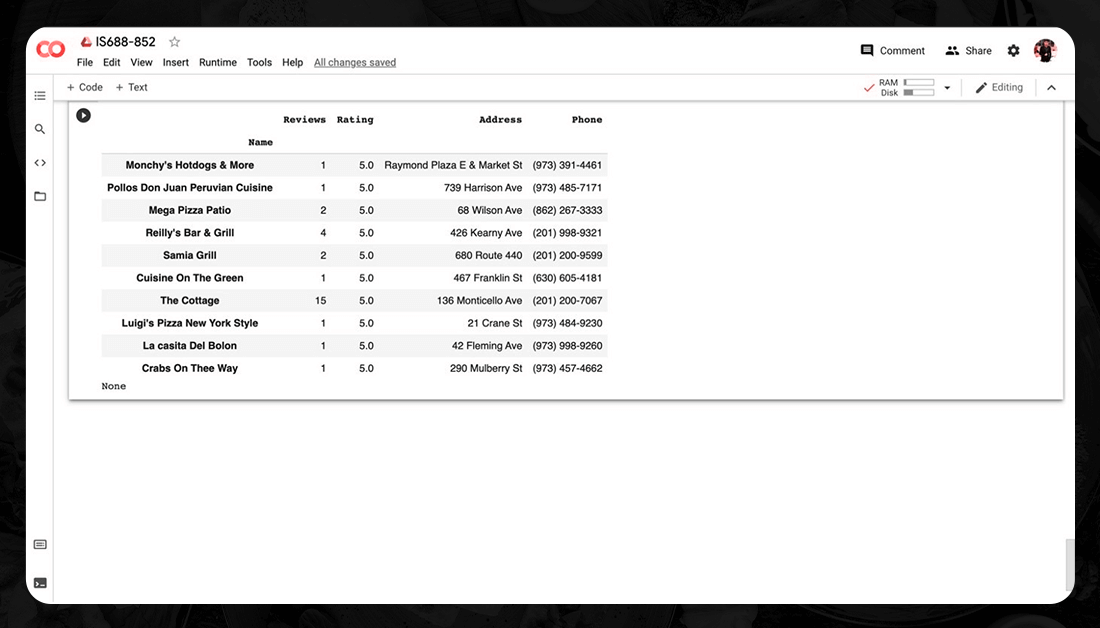
As it can be seen, the data includes details such as the phone number, address, rating, location, and reviews. It is completed by using Yelp's suggested parameters, that are included in the HTTP request's query string.

Another step was to use the for loop and go through the JSON text for getting the values for address, reviews, rating, phone, and name, then save the result on the database frame and print the same. The following outcome was obtained:

The data available is in a clear form but the duplicate values must be deleted.

To get rid of duplicate values, we first counted how many of them were in the database. After evaluating the data, we used the pandas method drop duplicates () for removing duplicated entries based on Phone Number, which is unique.

Duplicate values have now been eliminated from the data
After cleaning the data, you can use the describe() method to find out how many ratings and reviews of a restaurant has on an average. you learned that the number of ratings of a hotel is near '4', and the amount of reviews are near '152'.

Now when all this information is available, you can search for the major ten restaurants in the area with the best rating.
The number of restaurants represented on x-axis, while y-axis reflects the rating in the histogram above. There are over 200 restaurants having a '4.0' rating, over 150 restaurants with a '4.5' rating, and over 50 restaurants with a '5.0' rating.
This blog is a beginner's tutorial on restaurant data scraping and getting acquainted with the most often used libraries for online web scraping. This blog will teach you how to interact with APIs and how to use Python in performing data scraping and analysis. To sum up the findings, it is found that the most difficult part of this blog was locating the database, cleanup the data, and then understanding data scraping.
Looking for a scraping analysis of restaurants? Contact ReviewGators!
Feel free to reach us if you need any assistance.
We’re always ready to help as well as answer all your queries. We are looking forward to hearing from you!
Call Us On
Email Us
Address
10685-B Hazelhurst Dr. # 25582 Houston,TX 77043 USA
ReviewGators provides the Best Online Reviews API to help you access well-structured data of customers’ feedbacks.
© 2012 - 2025 ReviewGators, All rights reserved.
