Blog / How Web Scraping is Used to Extract Walmart Product Reviews and Ratings
31 January 2022

This blog will focus on creating a web scraper that replicates the browser behaviors required to scrape Walmart product reviews and ratings. Selenium has several useful features that aid in the automation of web page testing. Instead of requiring human labor, we will employ some of these capabilities to automate our scraper for your use case. This information can also be utilized for BERT analysis and other NLP applications.
The technique of obtaining structured web data in an automated manner is known as web scraping. Pricing monitoring, price intelligence, news monitoring, lead creation, and market research are numerous applications of web scraping. You've done the same duty as a web scraper if you've ever copied and pasted information from a webpage, although on a small, manual scale.
The requests library's web scrapers are semi-automated and frequently hard-coded for a specific need. Selenium Bots, on the other hand, are used to replicate browser behavior for heavy sites that employ JavaScript. You will need to install the chrome driver to connect your website with the code mentioned in this blog. Consider hiring a person with the duty of collecting evaluations for your product from all of Walmart's 1000+ pages.
Below mentioned is the step-by-step outline for web scrapers:
Initially, we will install the libraries required for the scraper:
pip install selenium pip install beautifulsoup4
Construct the browser object by using the selenium webdriver to configure our previously obtained driver path. To open our product URL, use the get attribute.
Here, we will successfully install and execute the basic operation on Selenium.
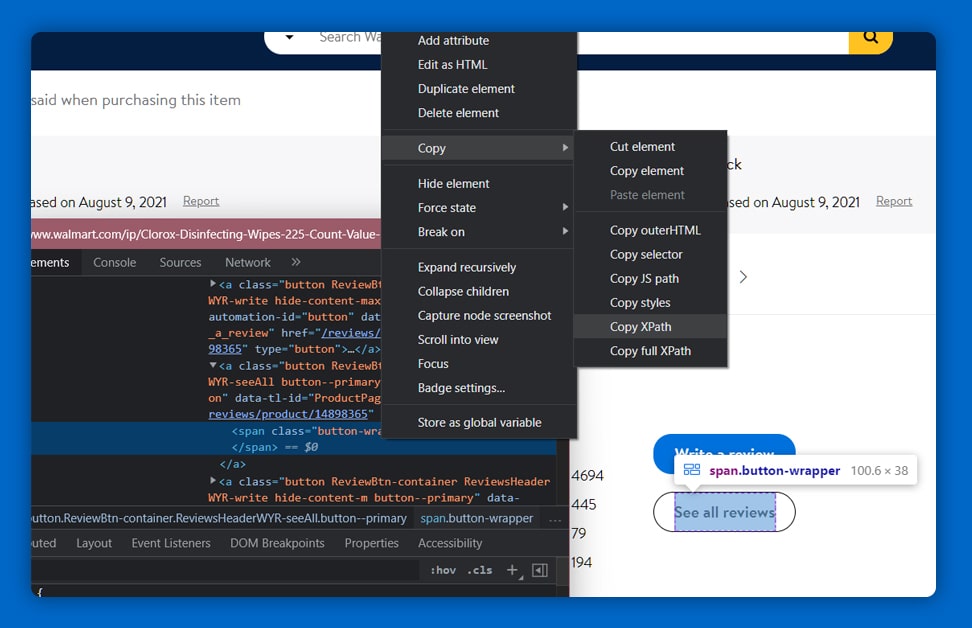
We utilize Selenium's ActionChains to do all of the click actions. To retrieve the product-id from the URL, use implicitly wait for the command to allow the website to load even before the error occurs.

Select, which replicates a manual process of picking an element from a list, from the dropdown category's Xpath. To access the reviews page, you will need to automate the steps.
For the reviews, loop through the appropriate number of pages.

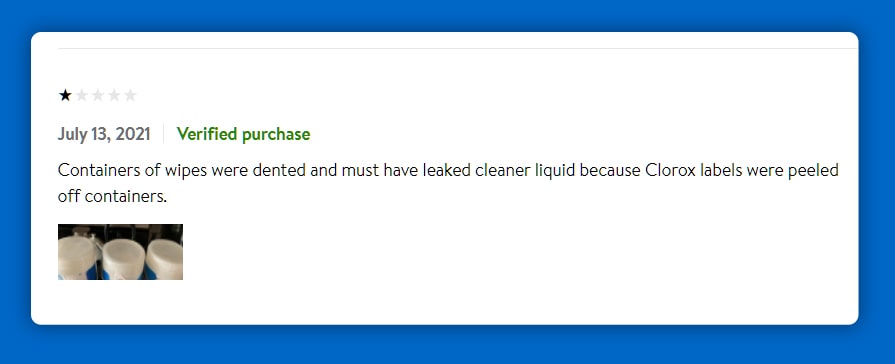
Review date, Reviewer name, Review title, Review body, and Ratings are the five elements you require for your evaluation. We can quickly locate the tags for each item.
Extracting the title of the reviews was difficult due to missing data. Scraping the titles of the reviews was difficult due to missing data. You will explore a few different approaches before deciding to utilize the length of the list containing the tags for the titles under the review header as a Boolean to determine whether we should add our tile list by the title or by a nan value.
Further, you will execute the below steps:
The DataFrame does not appear to be clean, and it is difficult to access. Converting the 'date' column into the DateTime index is a good decision here. For example, after December '20, You will search for the data. Your data is cleansed using the str.replace technique, which eliminates any undesirable substrings.
This completes your final output. To extract the product reviews, you will be able to construct a completely automated web scraper.
If you still wish to execute the code, here’s how you will initiate the project.
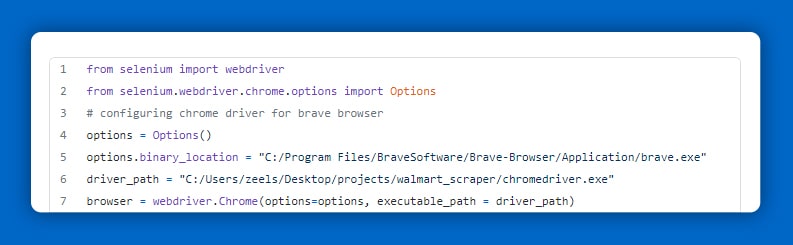
Implicit wait techniques might be problematic at times. As a result, you can use the waits function to provide an element that will be loaded before the script continues to run. Here's how to do it:
The following is an overview of the step-by-step approach we used to create a web scraper:
If you are looking to scrape the Walmart product reviews and ratings, contact ReviewGators now or request for a quote!
Feel free to reach us if you need any assistance.
We’re always ready to help as well as answer all your queries. We are looking forward to hearing from you!
Call Us On
Email Us
Address
10685-B Hazelhurst Dr. # 25582 Houston,TX 77043 USA
ReviewGators provides the Best Online Reviews API to help you access well-structured data of customers’ feedbacks.
© 2012 - 2025 ReviewGators, All rights reserved.
